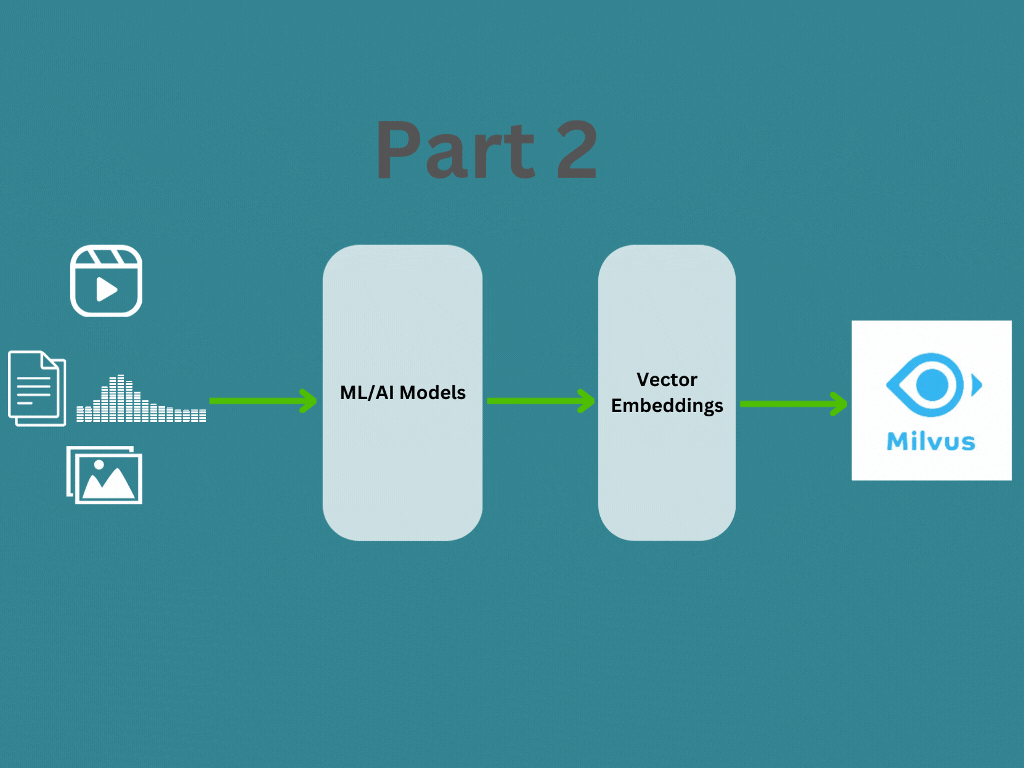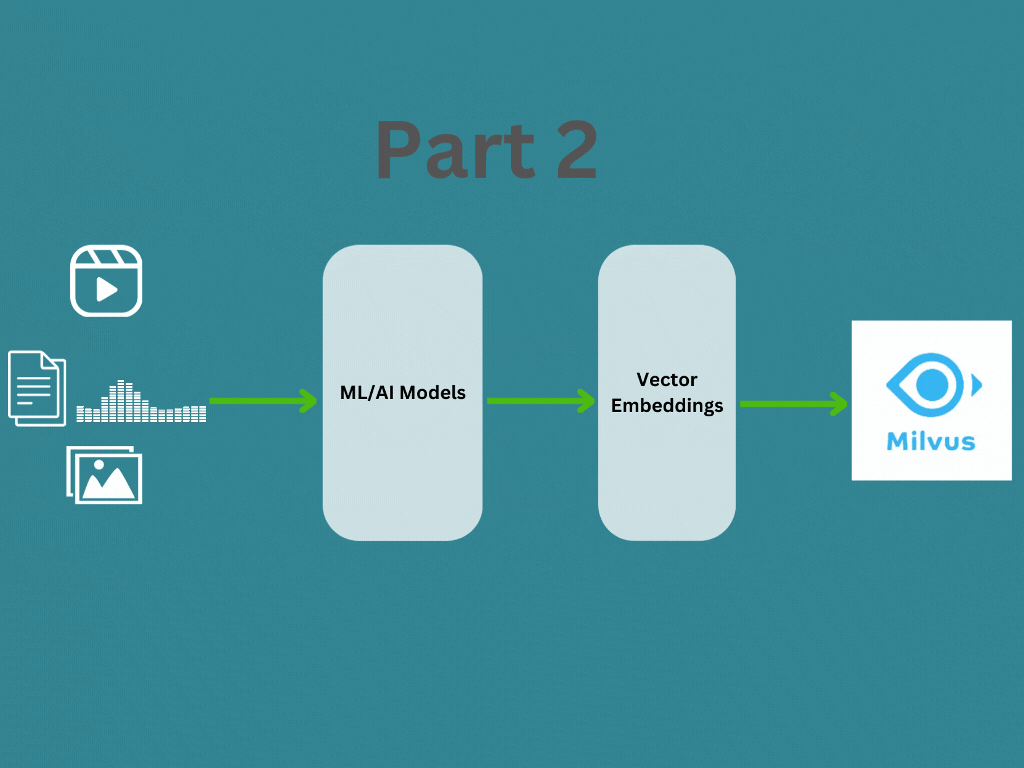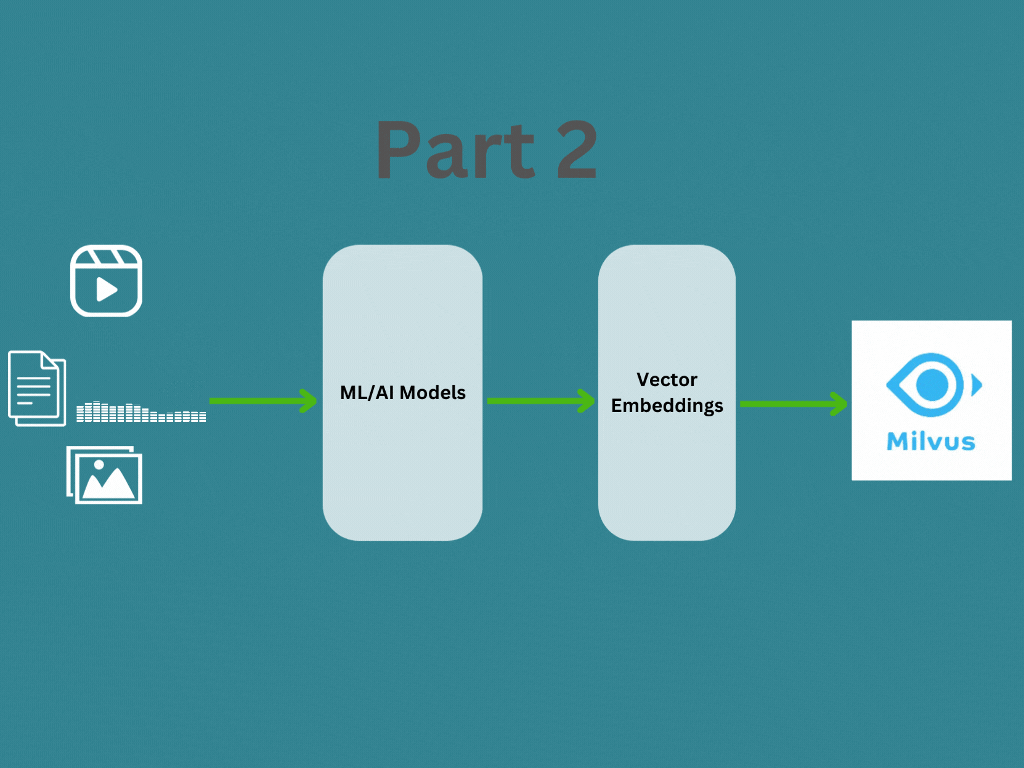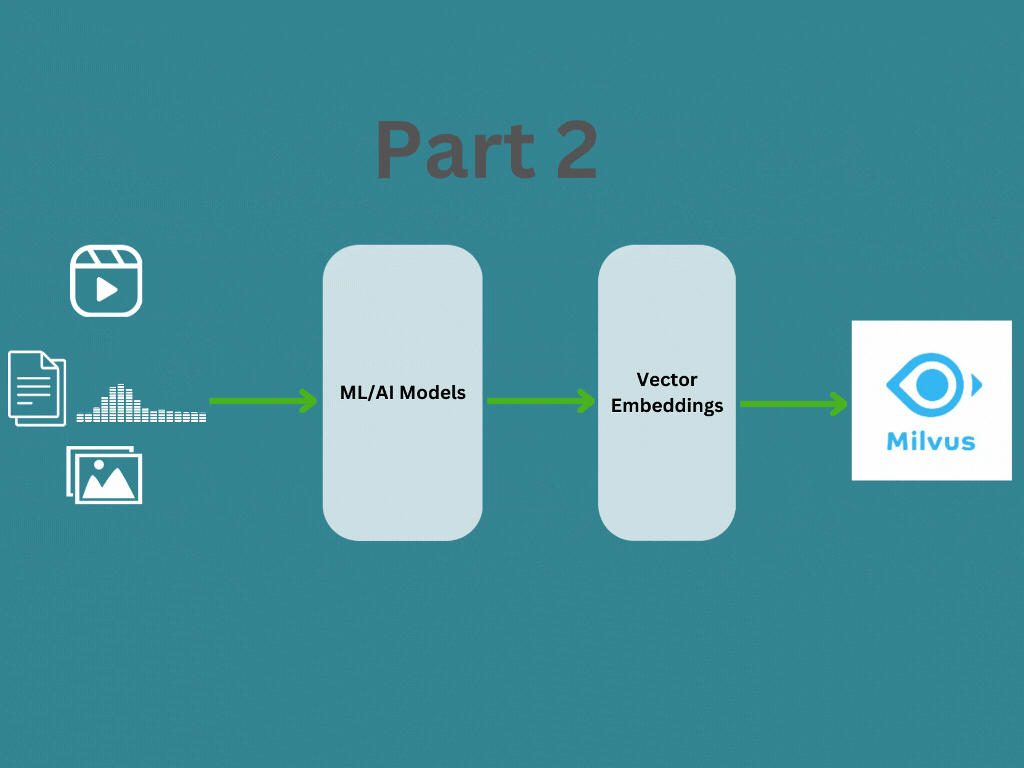
In Part 1, we covered about what are vector emdeddings and how to generate vector embedding for different data types. In this post we will learn about how the vector embeddings are managed and searched using a vector database like Milvus for your application. You can find the documentation here
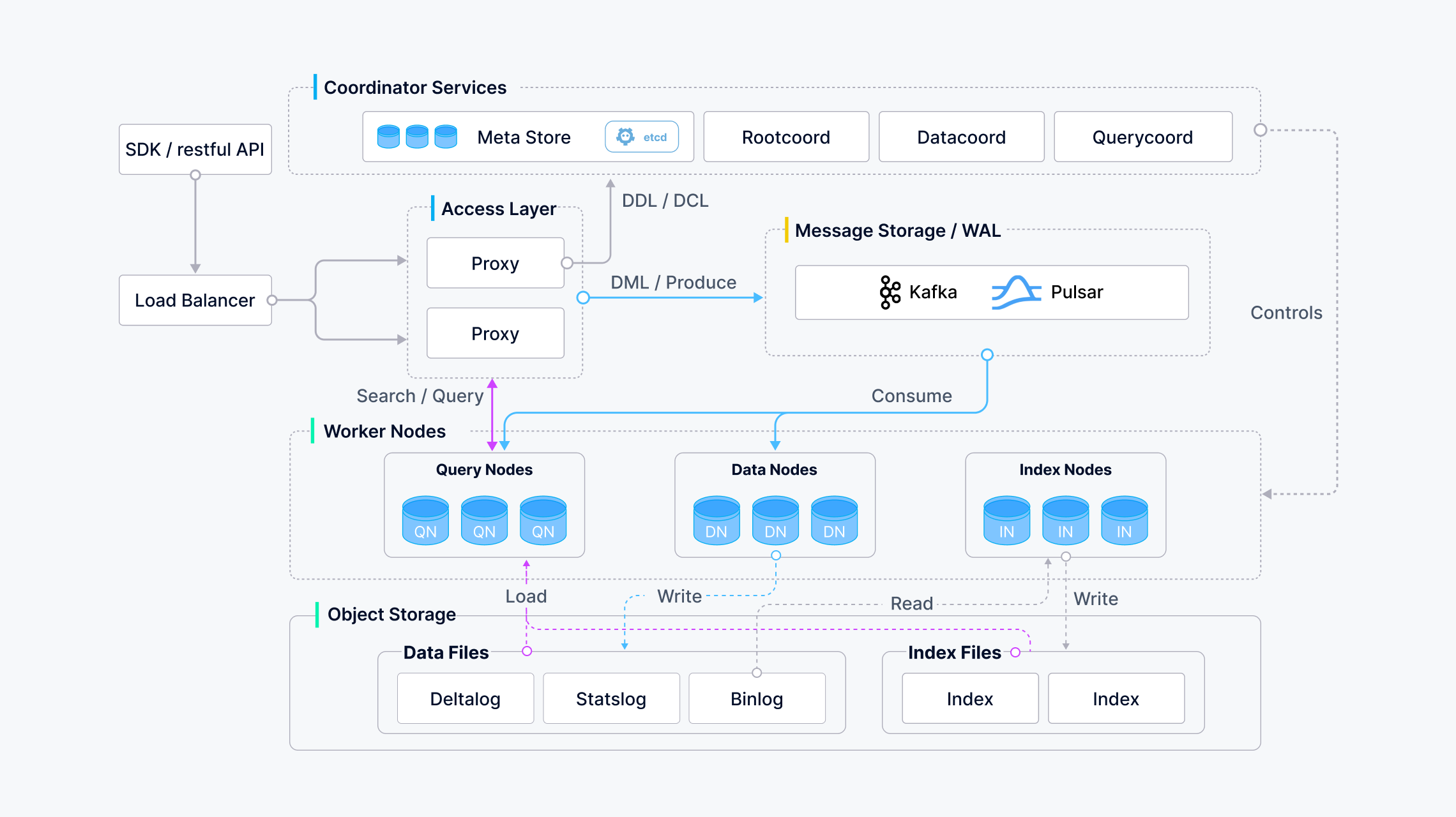
Architecture
Milvus is an opensource vector database build on top of popular vector search libraries including Faiss, HNSW, DiskANN, SCANN and more. It was designed for similarity search on dense vector datasets containing millions, billions, or even trillions of vectors.
Manage Databases
Similar to traditional database engines, you can also create databases in Milvus and allocate privileges to certain users to manage them. Then such users have the right to manage the collections in the databases. A Milvus cluster supports a maximum of 64 databases.
Create a database
| |
Schema, Collections and Index
In Milvus, you can create multiple collections to manage your data, and insert your data as entities into the collections. Collection and entity are similar to tables and records in relational databases. This page helps you to learn about the collection and related concepts. You can create and manage collections in two ways,
- From code (Python)
- From Attu (GUI)
Option 1: Create from code (Python)
When you are creating the collection via code you need setup the initialization step of schema, index and collection.
Create Schema
| |
Set Index Parameters (Optional)
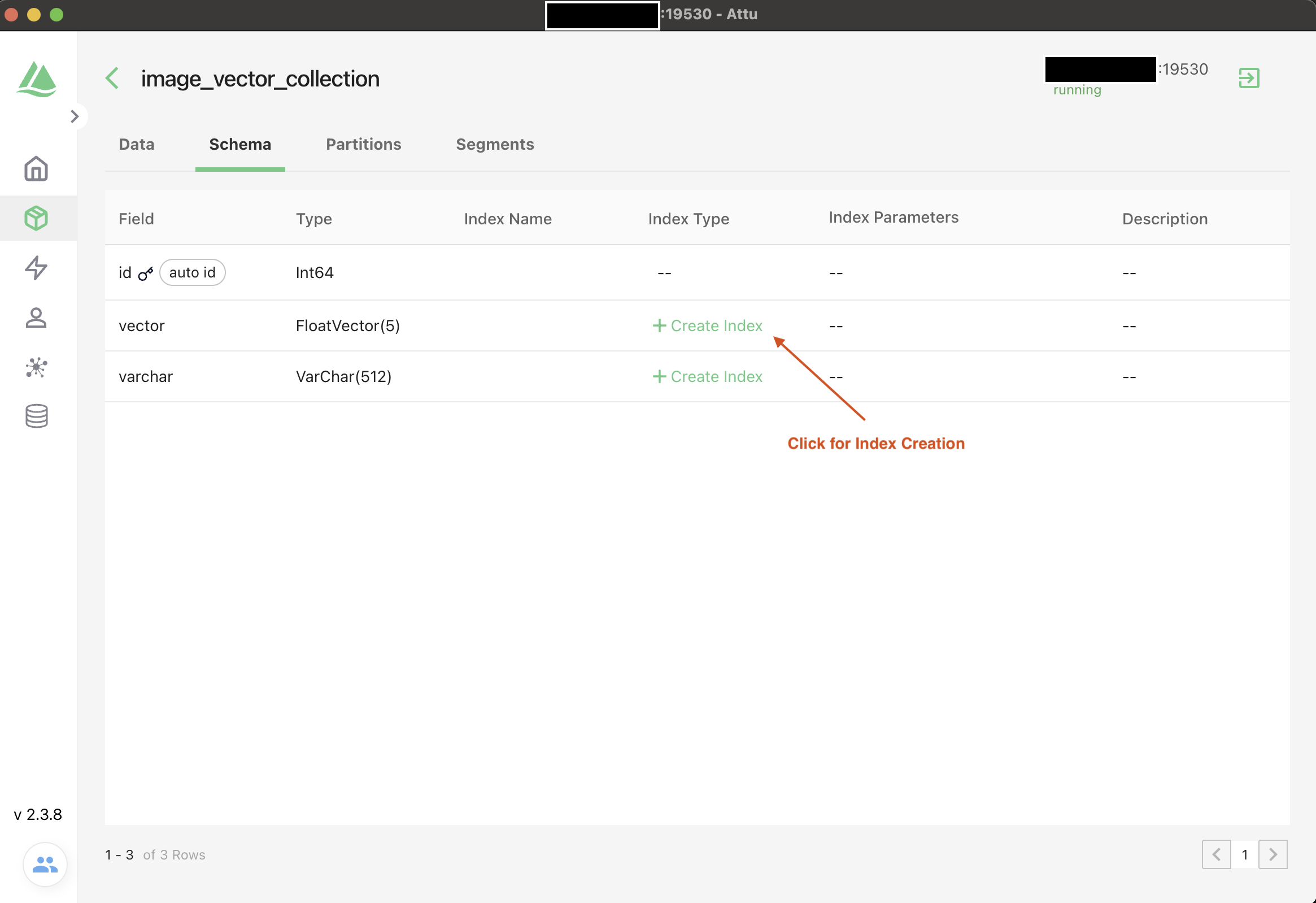
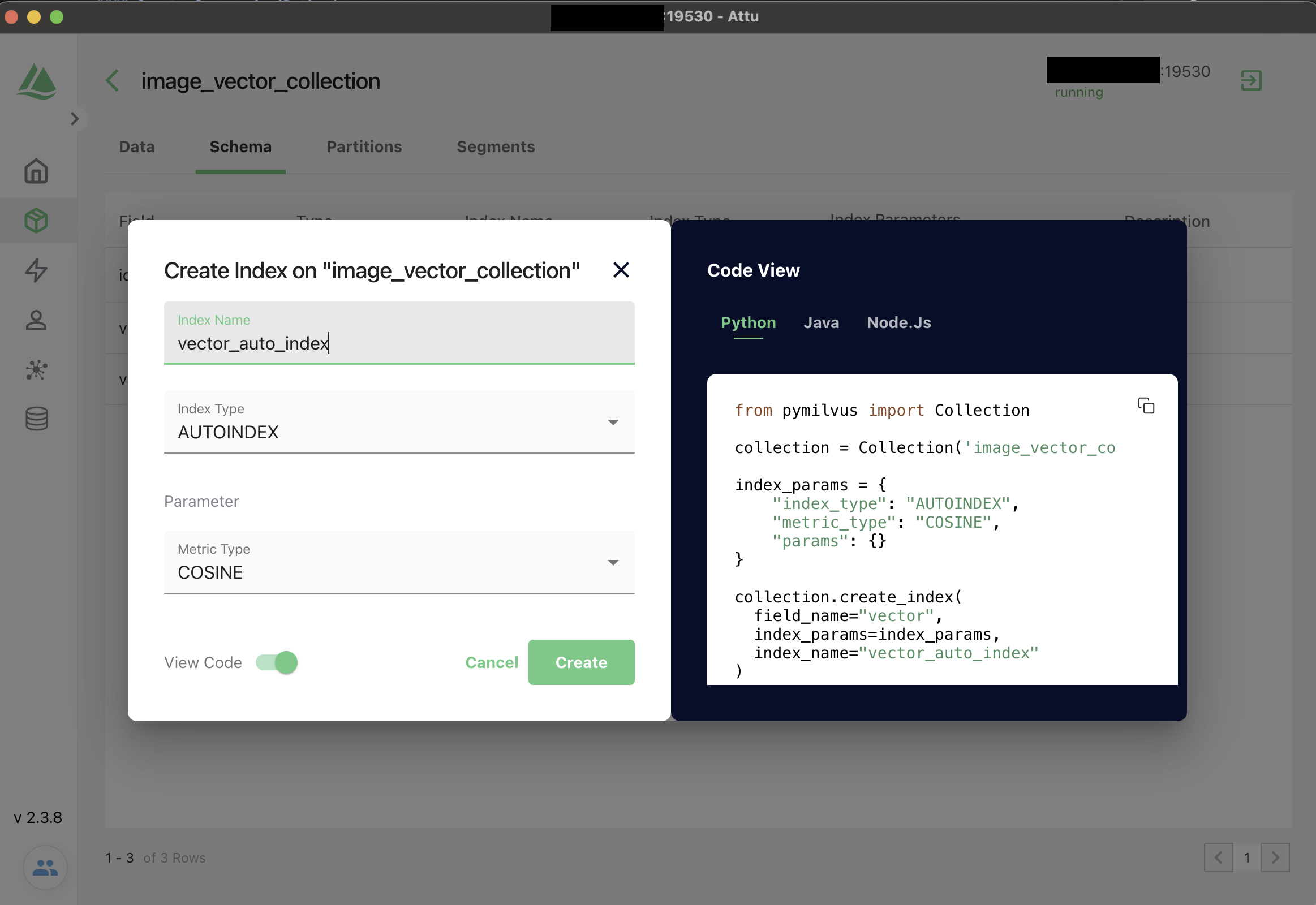
Creating an index on a specific field accelerates the search against this field. An index records the order of entities within a collection. As shown in the following code snippets, you can use metric_type and index_type to select appropriate ways for Milvus to index a field and measure similarities between vector embeddings.
In Milvus, you can use AUTOINDEX as the index type for all vector fields, and one of COSINE,L2, and IP as the metric type based on your needs.
| |
Create Collection
If you have created a collection with index parameters, Milvus automatically loads the collection upon its creation. In this case, all fields mentioned in the index parameters are indexed.
| |
You can also create a collection without any index parameters and add them afterward. In this case, Milvus does not load the collection upon its creation. The following code snippet demonstrates how to create a collection without an index, and the load status of the collection remains unloaded upon creation.
| |
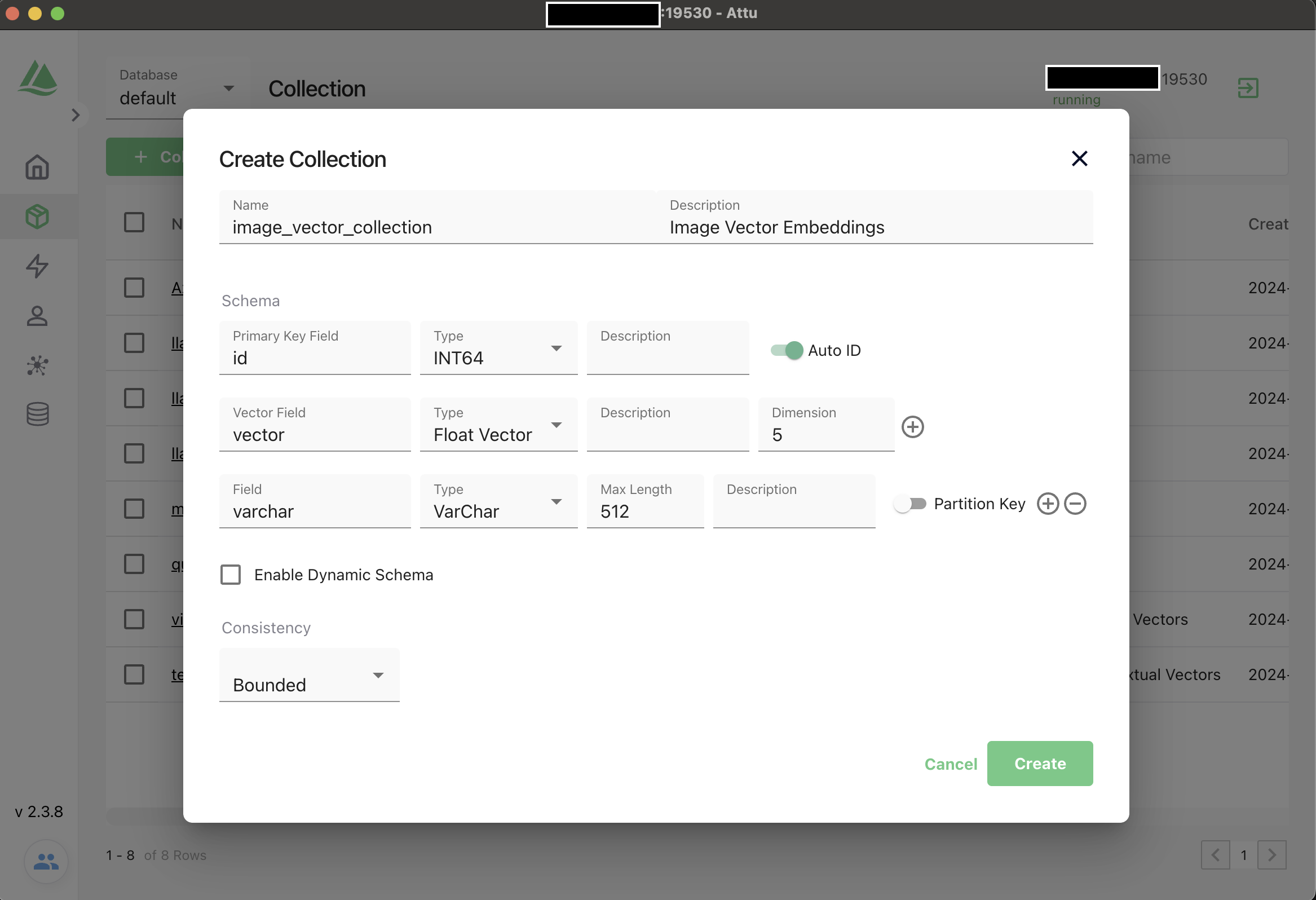
Option 2: Create from Attu (GUI)
Attu is the all in one milvus administration tool and attu version is coupled with the Milvus database version. Therefore always check the compatibility and use the recommended attu version for Milvus database version.
Create Schema and Collection
Create Index
Insert
Entities in a collection are data records that share the same set of fields. Field values in every data record form an entity.
Before inserting data, you need to organize your data into a list of dictionaries according to the Schema, with each dictionary representing an Entity and containing all the fields defined in the Schema. If the Collection has the dynamic field enabled, each dictionary can also include fields that are not defined in the Schema.
| |
Search
Once you have inserted your data, the next step is to perform similarity searches on your collection in Milvus. Milvus allows you to conduct multiple types of searches, depending on the number of vector fields in your collection:
- Single-vector search: If your collection has only one vector field, use the search() method to find the most similar entities. This method compares your query vector with the existing vectors in your collection and returns the IDs of the closest matches along with the distances between them. Optionally, it can also return the vector values and metadata of the results.
- Hybrid search: For collections with two or more vector fields, use the hybrid_search() method. This method performs multiple Approximate Nearest Neighbor (ANN) search requests and combines the results to return the most relevant matches after reranking.
The following code snippet demonstrates searching for the top 5 entities that are most similar to the query vector inside query_vector
| |
Useful links
- Milvus Docs - https://milvus.io/docs
- Milvus Demos - https://milvus.io/milvus-demos
- Youtube - https://www.youtube.com/c/MilvusVectorDatabase