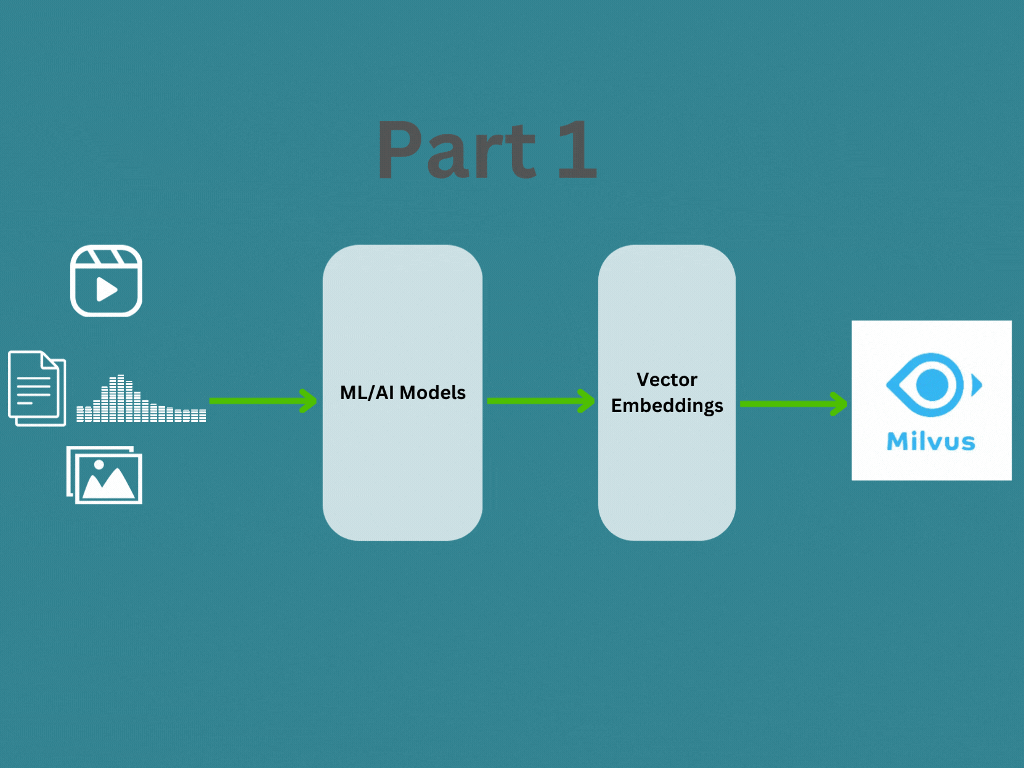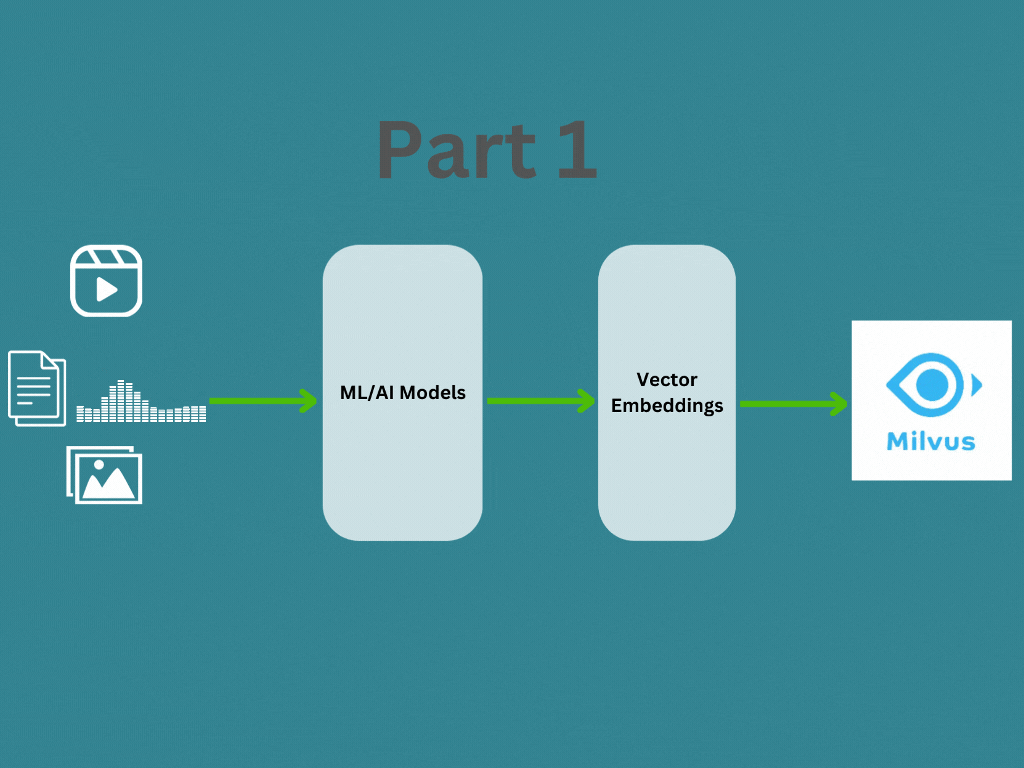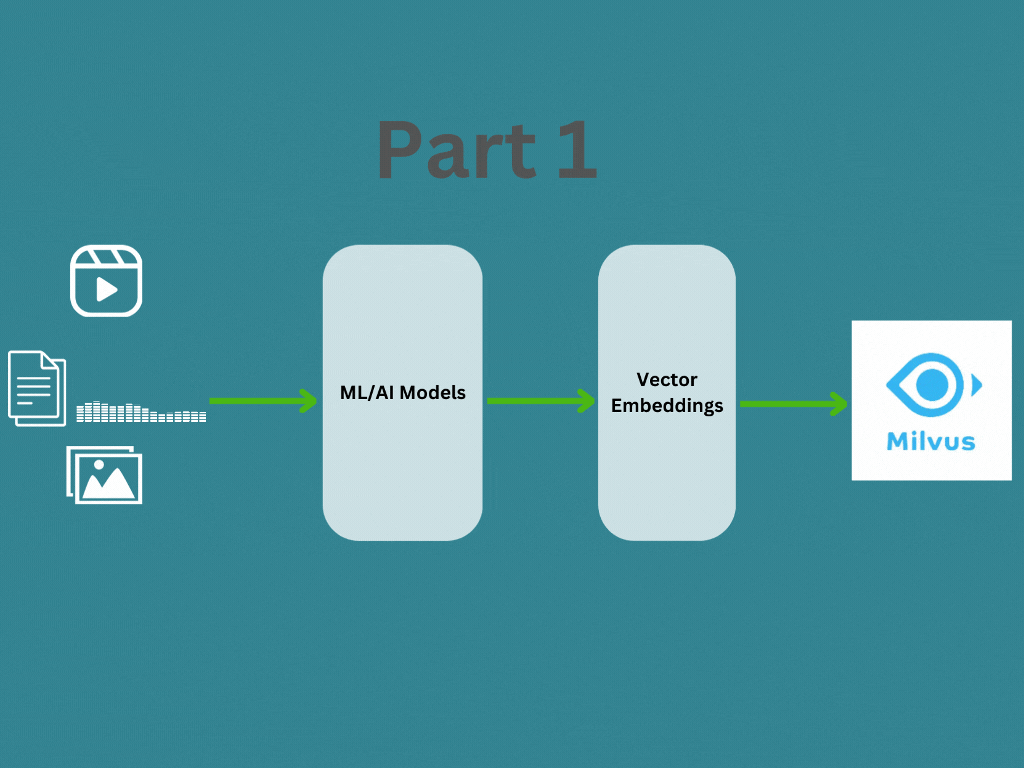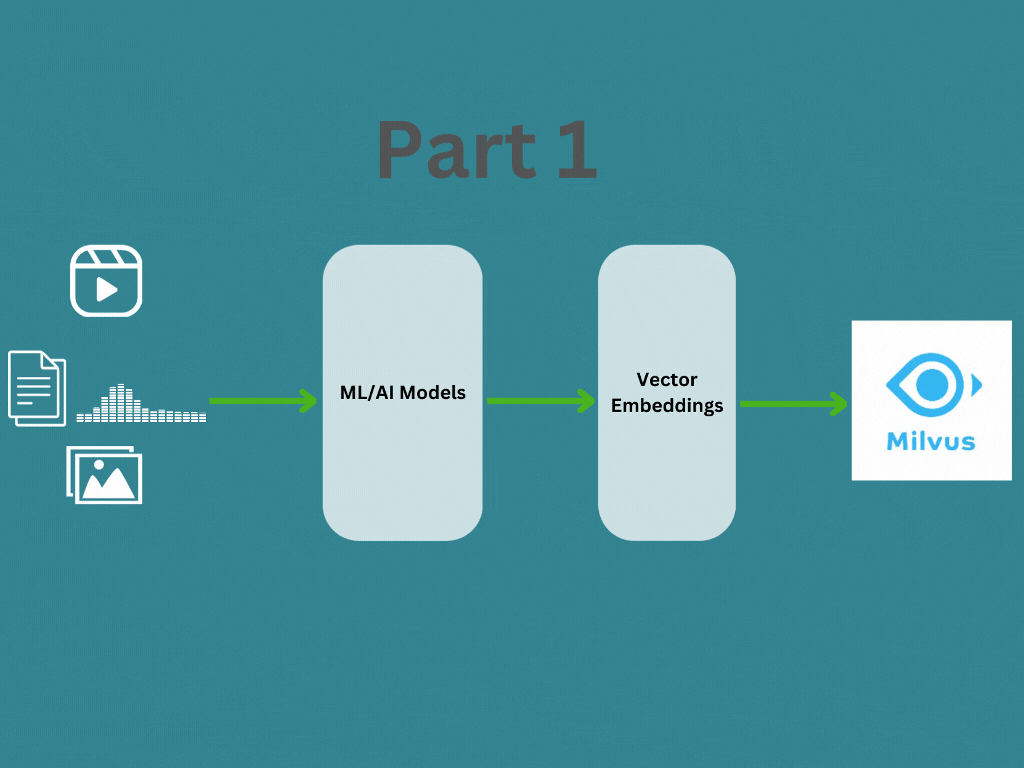
In this post, we will learn about what are vector emdeddings and how to generate vector embedding for different data types. In the Part 2 I will explain how the vector embeddings are managed and searched using a vector database like Milvus for your application.
What are vector embeddings?
Vector embeddings are a way to convert data (Text, Image, Audio, Video or any other form of data) into numbers that represent their meaning and relationship (refered as a quantity with both magnitude and direction in Physics). This allow us to represent data in a multidimentional space (Ex: Euclidean space) and similar data points will be clustered together.
There are different types of vector embeddings available and in this post we will not go into details of these types, but will list down some of the commonly used types. You can find all these models in Hugging Face (often called Github for Machine Learning) model repository.
Specially look out for ImageBind Research by Meta AI (The first AI model capable of binding data from six modalities at once, without the need for explicit supervision. By recognizing the relationships between these modalities — images and video, audio, text, depth, thermal and inertial measurement units (IMUs))
| Embeddings | Models |
|---|---|
| Text | GloVe, text-embedding-3-small, text-embedding-3-large |
| Sentece | sentence-transformers/all-MiniLM-L6-v2 |
| Image/Video | openai/clip-vit-base-patch32 |
| Audio | openai/whisper-large-v3 |
What is a vector database?
A vector database is the data store of vector embeddings and it indexes the data for fast retrieval, similarity search and CRUD operations. An opensource vector database like Milvus is purposely build for handling millions or even billions of vector embeddings for fast and accurate retrieval.
Vector databases, index vectors using multiple techniques like hashing, quantization or graph based techniques. Also for the query they relies on mathematical methods knows as simlarity measures (Cosine similarity, Euclidean distance, Dot product etc …).
Which applications are using vector databases and vector embeddings?
As we now know that vector embedding is a numerical representation of the data (Text, Image, Audio, Video or any other form of data) in vector space. The purpose of the vector embeddings to capture the semantic or contextual relationships between different entities. Where entities with similar meaning, context or features will be represented as vectors closer to each other in vector space. Due to this capability it makes useful in various applications across vaious fields and here are few examples.
- Anomaly Detection - Anomoly detection algorithms do identify unusual patterns or outliers in data and these anomolies can be found in various domains like fraud detection, network security and healthcare etc … This will come in handy for Cyber Security applications such as SIEM, SOAR, EDR/XDR etc …
- Object Detection and Classification - Classifying and detecting objects in a Image/Video.
- Question Answering Systems - Semantic search capability will allow to find the most similar question or question and answer pair for a given query. Once the closest question is identified, the corresponding answer will be the relevant answer for a given query.
- RAG (Retrieval-Augmented Generation) - This will allow the Large Language Models (LLM’s) with an internal or external knowledge base, which is outside of its training dataset to generate an accurate and reliable response to users query. This internal or external knowledge base can be a vector database with relevant information. Ex: An organizations internal information (Documents, Audio/Video recordings, Emails etc …) can be converted into vector embeddings and when an internal user wants to query specific information, it can accurately retrieve the relevant information and provided to LLM for the response generation. In this way it will reduces hallucinations, which is one of the major challenge when we are using LLM with GenAI applications.
- Recommendation Systems - These systems will work without any user interaction, where it will analyse user behaviour to discover user’s needs and interests. Recommendation Systems can convert entities (Movies, E-commerce Products etc ..), user’s behaviour in to vector embeddings and use similarity search to match which entity vectors are closer to users vectors.
- Search Engines - By converting entites (Web pages, Articles, Movies, E-commerce Products etc …) into vector embeddings, we can retrieve information relevant to the users search queries.
How vector embeddings generated?
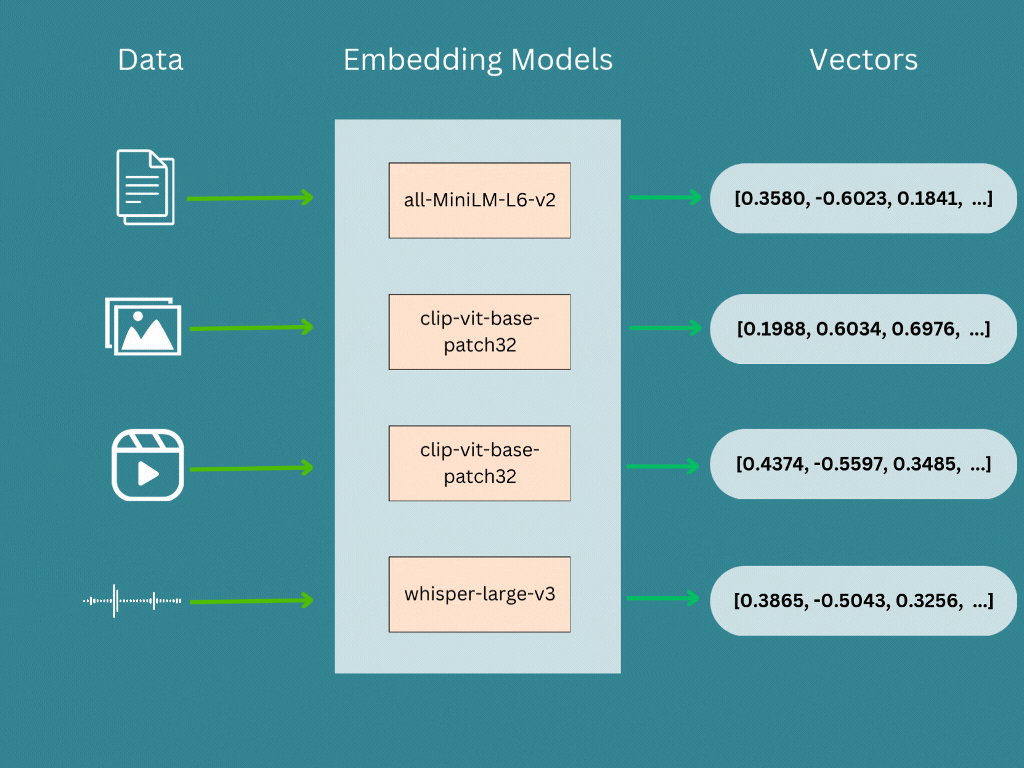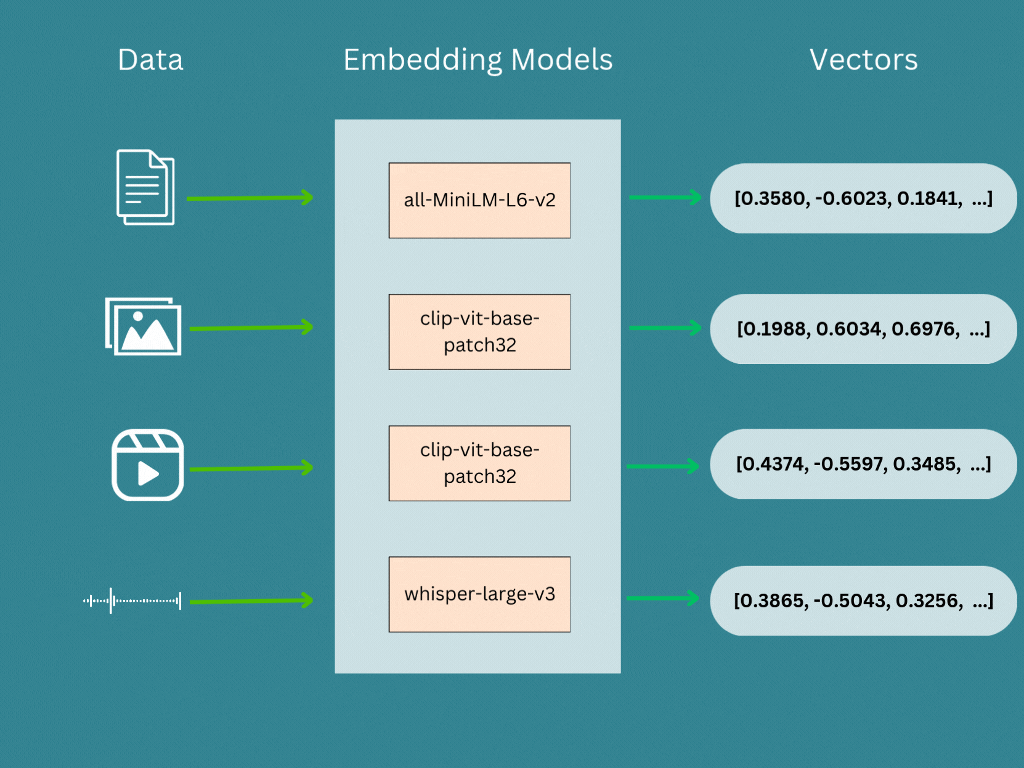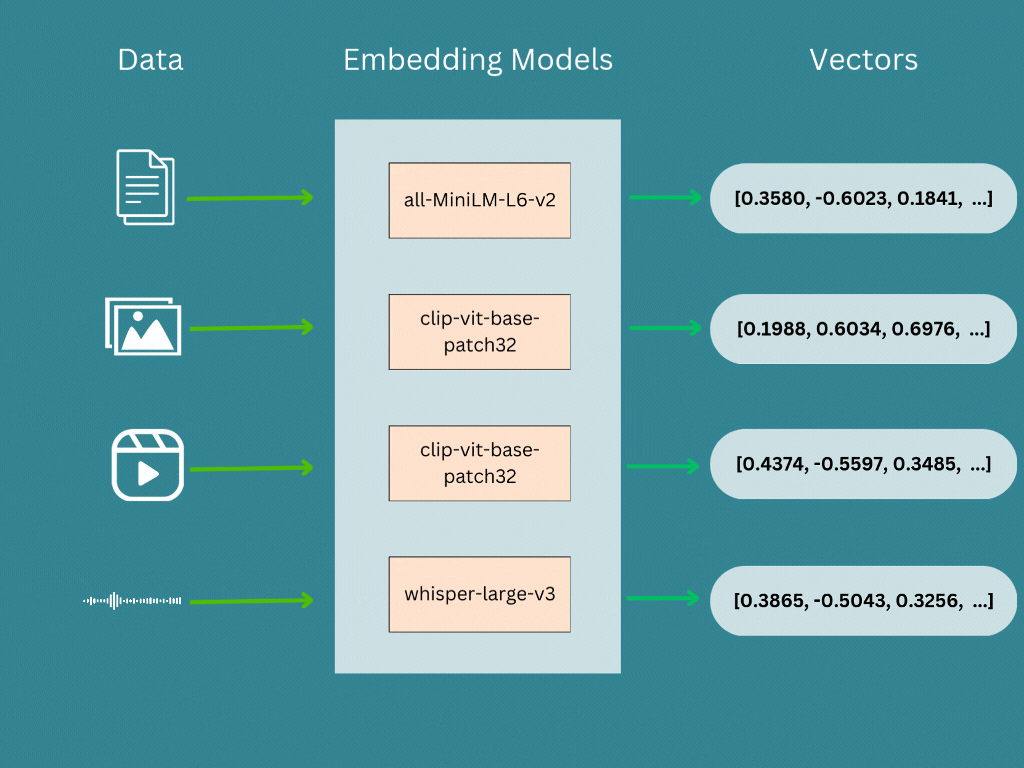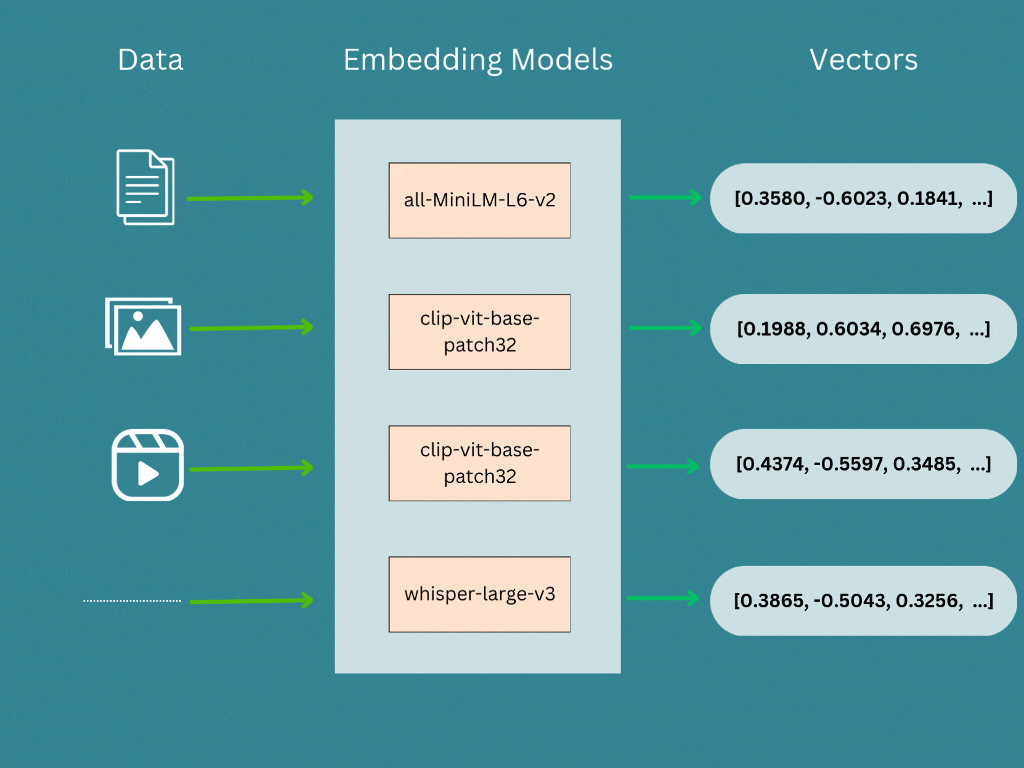
Vector embedding are generated by a embedding model or a deep neural network, where its the internal representation of the input data within the model. When we run our input data (Text, Image, Audio, Video etc …) through a pre-trained model, the embeddings are the output of second-to-last layer and models prediction is the last layer. Therefore we will take the second-to-last layer’s output as the vector embeddings.
Note : Most important thing to keep in mind is that, depending on our requirement we have to select the proper embedding models.
As Example: You cannot generate embedding for an image using Sentence Transformer model (like sentence-transformers/all-MiniLM-L6-v2), because this pre-trained model is trainined with Text/Sentence dataset and not with Image dataset.
How to generate vector embeddings?
In this section we will understand how we can generate vector embeddings using different embedding models. As I mentioned above, the most important aspect is finding the right model for your input data (Text, Image, Audio, Video etc …). This article from Zilliz provide more information about different embedding models available and always you can find more in Hugging Face as well.
1. Text Embeddings
| |
2. Sentece Embeddings
| |
3. Image Embeddings
| |
Go to Part 2